ニューラルネットワーク(深層学習, Deep Learning)をはじめとする機械学習の技法を用いて, 画像認識, 自然言語処理, 認知情報処理(人間の視覚,言語,感性情報)についてのテーマを扱っています.とりわけ人の学習機構のモデル化, アルゴリズムを考案することにより, 計算機上での応用を試みています.
上記のアイコンをクリックすることで, 該当ページに移動することができます.
画像認識

画像認識とは, 「コンピュータが、対象とする画像中に写っている物体を識別する技術」です.つまり「眼を獲得しよう」という研究分野になります.身近な例では, スマートフォンの顔認証が挙げられます.
私達はどのように物体を認識しているでしょうか.例えばライオンは, 茶色の毛が生えた4本足の動物で, 尻尾や顔の周りにタテガミがあって…といった特徴と照らし合わせています.固有な特徴を掴んで記憶することで, 距離や角度が異なっている状態であっても, その違いに対応して識別することができるのです.一方, コンピュータにとっては難易度の高い課題となっています.なぜならコンピュータは画像を画素の集合体としか捉えていないからです.言い換えると, 数字(画素値)の羅列です.
以上の理由から, 画像認識は思うような成果を挙げることができませんでしたが, 2012年に登場した「ディープラーニング」によって飛躍的に精度が向上しました.ディープラーニングとは, 人間の脳内に存在する神経回路を模倣したニューラルネットワークを多層に積み重ねたもので学習することです.一言でいうと, 「人間の学習を数理モデルで再現する」ということです.従って, ある物体を見つけるための限りなく近似された関数を見つけ出そう!という試みになります.
画像認識には畳み込みニューラルネットワーク(Convolutional Neural Network, 以下CNNと略す)と呼ばれる手法が広く用いられます.CNNは特徴を抽出する畳み込み層と, 情報量を圧縮することで平行移動の頑健性を高めるプーリング層から構成されます.つまり画像中の物体の輪郭を認識し, その位置がズレたとしても認識できるようにしていると言うことです.従って, 私たちと同様のプロセスを踏んで認識しようとする試みになります.このような手法を駆使することで, 2022年4月時点では80%後半程度の高い精度を出すことに成功しています.近年では注意機構を用いたVision Transformer(ViT)が成果を上げています.そのため製造業やモビリティ, 医療といった多岐に渡る分野で応用されています.
画像認識技術は大きく分けると物体認識, 物体検出, セグメンテーション, 画像キャプション生成に分けることができます.当研究室では, これらの中でも特に物体検出, セグメンテーションの研究に力を入れています.
物体認識
物体認識とは, 画像中において予め指定された複数種類の物体の内, どの種類の物体が存在するかを識別する手法になります.
具体的にはコンピュータが, 指定された物体である確率を算出して, その値が最も高い物体を採用するアルゴリズムになります.
例えば右の図のように, コンピュータがこの代表的な物体は電車の確率が80%, バスの確率が15%, 船の確率が5%と算出した場合, この画像に写っている物体は「電車」と判断することになります.

物体検出
物体検出とは, 画像中において, 予め指定された複数の物体の種類, 位置, 個数を識別する手法です.
具体的には物体ごとに切り出し, それらの種類と確率を算出するものになります.
物体認識と異なる点は, 1種類だけではなく複数の種類の識別が可能であることと, その位置を矩形領域として切り出すことができることです.
Faster R-CNN, YOLO, SSDが代表的なモデルとなっています.

セグメンテーション
セグメンテーションはセマンティックセグメンテーション, インスタンスセグメンテーション, パノプティックセグメンテーションの3種類に分けられます.セマンティックセグメンテーションとは, 画像の最小単位である画素に対して物体の種類を識別する手法であるため、その高い正確性から注目を集めています.セマンティックセグメンテーションの精度向上を目的として, 様々なアプローチから研究を行っています.
ⅰ.前処理として, 入力画像に対して代表色画像を作成
ⅱ.ケーソン式防波堤の隙間検出モデルである3D-2D-CNNの改良
ⅲ.深度マップや顕著性マップを入力に追加
画像キャプション生成
画像キャプション生成とは、入力された画像に対して適切な説明文を生成する手法です。マルチモーダル研究と呼ばれる, テキストと画像の2つの領域にまたがっていることから有用性が高い研究となっています.
ⅰ.深度情報を追加
ⅱ.BOSトークンに2種類の特徴量を与える
画像生成
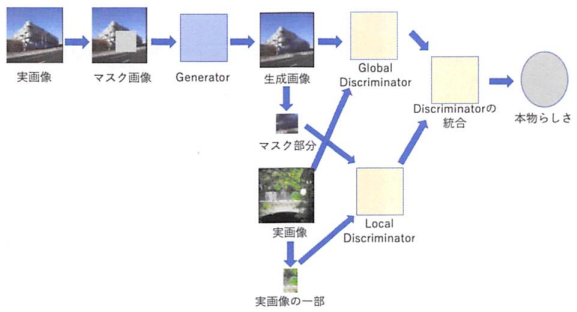
画像生成とは, 入力された画像から特徴を抽出し, それを用いて実在しない画像を新たに生成する手法です.スタイル変換や敵対的生成ネットワーク(Generative Adversarial Networks:GAN)などに代表される様々な生成モデルが考案されています.例えば, スタイル変換は実在する画像のスタイルを変換した画像を生成することができます.また, GANは白黒画像をカラー化することや, 欠損領域を補完することができます.これらを発展させて, 生成画像の自然さや生成時間の短縮化など, 多様化する目的を対象とした研究となっています.
時系列予測

時系列予測とは,「コンピュータが,時間的な経過に伴って変化する様々なデータから規則性を見つけ出し,将来どのように変化するのかを予測する技術」です.つまり, 「以前の情報から未来を推測しよう」という分野になります.これは自動車の運転等あらゆる場面で人間も行なっている活動です.身近な例では, 台風の進路予測が挙げられます.
時系列予測では再帰型ニューラルネットワーク(Recurrent Neural Network, 以下RNNと略す)やTransformerベースのモデルが数多く提案されています.RNNは内部に循環するような閉路を設けることで一時的に情報を記憶することができるネットワークになります.代表的なRNNとして, Gated Recurrent Unit(GRU)やLong Short-term Memory(LSTM)が挙げられます.Transformerは注意機構をメインに構成されたRNNとは全く異なるネットワークになります.
ここで動画データを扱う場合を考えてみましょう.動画は複数枚の画像を高速で表示することで画像中の物体の動きを表現するものです.つまり画像の集まりということになります.そのため, 画像情報を抽出するCNNと時系列情報を記憶するRNNを複合したConvolutional GRUやConvolutional LSTMが提案されています.また, Transformerや拡散モデルをベースにしたモデルが提案されています.
時系列予測技術は交通, 金融, ロボット制御, 医療, 気象等多くの分野へ応用することが可能であり, その効果が期待されています.当研究室では, これらの中でも特にドライブレコーダを対象とした動画予測, 株価騰落予測の研究に力を入れています.
動画予測
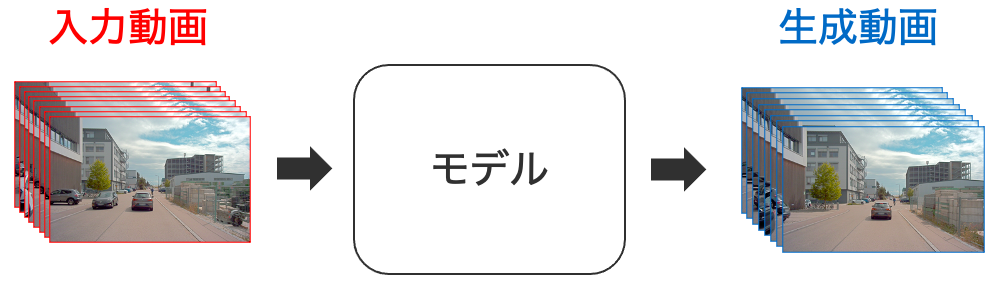
動画予測とは, ある動画の後続の動画を予測して生成するタスクになります.例えば10秒間の動画を対象にした場合, 最初の8秒間の動画から残りの2秒間の動画を予測して生成するということです(秒数は任意).
このタスクは,交通,医療,気象,ロボット等の多種多様な分野に応用可能となっていることから注目を集めています.本研究室では,自動運転技術の安全な社会実装が急務とされている交通分野に着目して,車載動画(ドライブレコーダの動画)を対象とした研究を行なっています.
先行研究として提案されているモデルはRecurrent Neural Network(RNN)ベース,Convolutional Neural Network(CNN)ベース,Vision Transformer(ViT)ベースのモデルが挙げられます.しかしながら,車載動画のような複雑な状況変化をする動画に関しては,十分な性能を発揮できていないことが現状となっています.
こういった課題を解決することができるモデルの開発や学習手法の改良に取り組み,一定の成果を上げています.
株価騰落予測
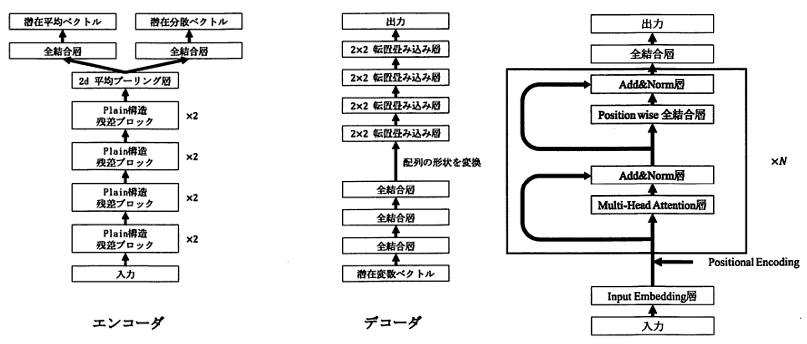
低金利が続く日本において投資は長く注目されてきました.株式の価格予測は効果的な資産運用を行うためにも重要な手法となりますが, その予測は極めて困難なものになっています.金融時系列データの規則性を解析する手法として機械学習がよく用いられ, 特に金融時系列データを時系列データ画像として用いる研究は成果を上げています.そこで日経平均先物の日足データを用いて騰落予測を行います.日足データからローソク足チャートを生成し, それをサブチャートに分割します.そして変分オートエンコーダを用いてサブチャートの次元削減を行い, 得られた時系列特徴ベクトルからTransformerのエンコーダを用いて学習することで, 5日後の騰落予測を試みました.
自然言語処理

自然言語処理とは, 大量のテキストデータをAIが分析する技術のことです.自然言語とは, 人間が日常でやり取りする日本語や英語などの, いわゆる言葉のことで, 自然言語処理はそのような自然言語を処理, 分析する技術です.この技術は, 対話型AIチャットボット, 機械翻訳, 検索システムなどに使用されており, 私生活ではDeepLという高精度の機械翻訳を目にする場所が多くなってきました.本研究室では, 会議の議事録を可視化する手法や, 裁判の判例文書の要約などの研究を行なっています.
自動要約
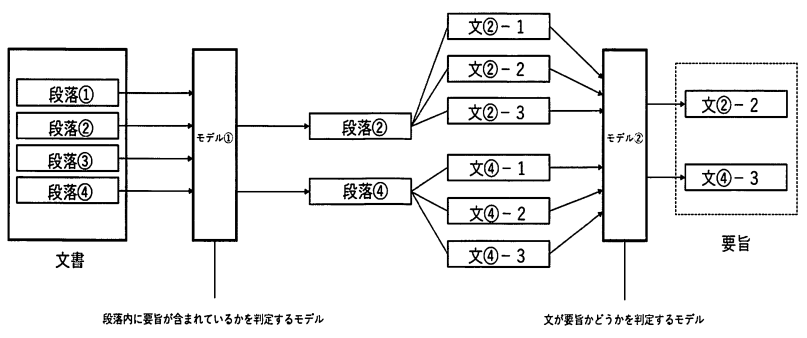
裁判の判決文から裁判の要旨を抽出する研究の紹介をします.データの対象は, 最高裁判所のホームページで公開されている判決データです.本研究では, 先行研究である文および段落のベクトル化, 要旨抽出のためのLSTMモデルの改善を試みました.一文の文字数が多い裁判の判決文に対し, Text CNNを用いて一文をより次元数の少ない文ベクトルに変換することで, 文章処理に必要な計算量をより削減.また, 段落ごとに要旨を判定する LSTM モデルをAttention付きLSTMに改良することによって, 段落間の関係性も重点的に学習させる構造を提案しました.以上の改良をもとに本研究においては, まず対象文書中, 要旨を含む段落を予測し, 次に要旨を含むと予測された段落中の各文を対象に要旨かどうかを予測するという二段階方式によって要約文の抽出を行いました.
認知情報処理

認知情報処理とは, 人間の視覚, 言語, 感性をコンピュータ上でモデル化し, 再現できるようにする研究分野です.本研究室では, 視認性, 図地の分離(物体と背景を見分ける), 奥行き認識などの人間の視覚野のモデル化, 言語獲得(人がどのように言葉を獲得していくか)のモデル化の研究を行なっています.そしてこれらの研究成果をパターン認識, 自然言語処理, データ解析における実際の問題を対象に応用することを試みています.
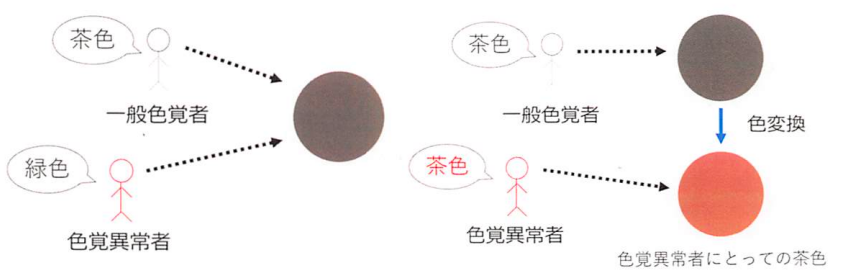
色覚異常者色同定支援
色覚異常者が不便に感じる場面として,例えば,色名を用いたコミュニケーションで齟齬が生じることが考えられます.その不便が生じる原因は,色と色名を結びつける「同定」が色覚異常者にとって困難なことにあります.そこで,色の同定を支援するために色変換を行う研究を行っています.提案手法では,色を見せたときにそれが何色と答えるかを予測するニューラルネットワーク(色同定ニューラルネットワーク)を用います.ニューラルネットワークの学習データには,被験者の方に色見本カードを見せ,それが何色かを尋ねる色同定実験の結果を使用しました.